Upload Large Data To S3 Bucket As Csv Hive Query

Alright, folks, gather 'round! Let me tell you a tale – a tale of massive datasets, the cloud-behemoth that is S3, and the valiant, occasionally grumpy, hero that is Hive. It's a story as old as time... or at least as old as AWS got serious about selling cloud services. Buckle up!
So, picture this: You've got this gigantic CSV file. We're talking "takes-longer-to-open-than-it-takes-to-make-coffee" gigantic. Maybe it's user data, maybe it's IoT sensor readings from millions of smart toasters (the future is now!), who knows? The point is, it's huge. And you need to, like, analyze it.
Your first thought might be, "Load it into Excel!" Don't. Just… don't. Trust me. I've seen things. Things no human was meant to see. Excel chokes. It weeps. It begs for mercy. You'll end up with more error messages than actual data. It's like trying to feed a whale a single goldfish cracker.
Must Read
S3: The Cloud's Filing Cabinet (Except Way More Complicated)
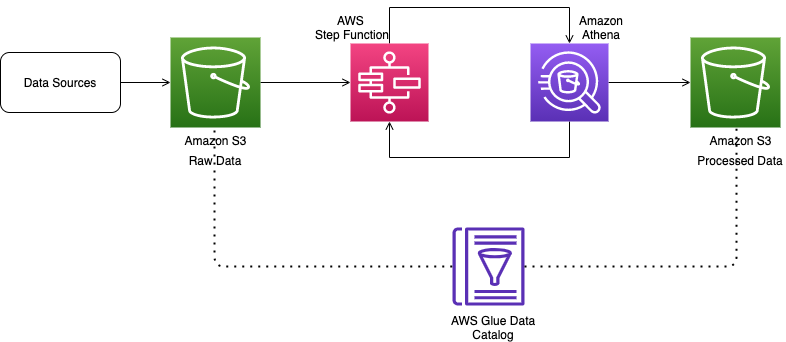
Enter S3, Amazon's Simple Storage Service. Think of it as a giant, infinitely scalable filing cabinet in the cloud. You can dump pretty much anything in there, and it’ll happily store it for a (reasonable…ish) fee. It’s like that storage unit you swear you’ll clean out someday, but instead of old furniture and dusty boxes, it’s full of… well, your giant CSV file.
The key here is speed and scalability. Uploading directly from your laptop is like trying to fill the Grand Canyon with a teaspoon. It’ll take forever. Instead, you want to use a tool like the AWS CLI (command-line interface). You can use commands like aws s3 cp your_massive_file.csv s3://your-bucket-name/.

Pro tip: Break up the CSV into smaller chunks for faster uploads! Think of it like moving boxes. Easier to move ten smaller boxes than one ridiculously heavy one. Nobody likes a herniated disk, least of all your computer.
Another fun fact: S3 is so reliable, it's rumored that even cats keep their important catnip stashes there. Okay, maybe not. But it's pretty darn reliable.
Hive: Making Sense of the Chaos (SQL to the Rescue!)
Okay, the beast is in S3. Now what? You can't just stare at a giant CSV in a bucket and expect insights to magically appear. That's where Hive comes in. Hive is like a translator. It lets you query data stored in S3 using good ol' SQL. Yes, that SQL! Even your grandma understands SQL… probably.

Hive essentially turns your CSV file into a table. A virtual table, mind you. It doesn't physically move the data. It just reads it from S3 and lets you slice and dice it with familiar SQL queries. Think of it as putting on your fancy data-analyst monocle and saying, "Ah, yes, let's see what secrets this CSV holds!"
Here's a simplified example of how to create a Hive table from your CSV:
CREATE EXTERNAL TABLE your_table_name (
column1 STRING,
column2 INT,
column3 TIMESTAMP
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION 's3://your-bucket-name/';
Let's break that down:
CREATE EXTERNAL TABLE: Tells Hive you're creating a table based on external data (i.e., your CSV in S3).your_table_name: Give your table a snazzy name. Something like "smart_toaster_data" or "customer_purchases_2024".column1 STRING, column2 INT, column3 TIMESTAMP: Defines the structure of your table. You need to know the datatypes of your columns (string, integer, timestamp, etc.).ROW FORMAT DELIMITED FIELDS TERMINATED BY ',': Tells Hive that your data is comma-separated. If you're using tabs, use'\t'instead.STORED AS TEXTFILE: Specifies that your data is stored as a plain text file (CSV).LOCATION 's3://your-bucket-name/': Points Hive to the location of your CSV file in S3.
Important: Make sure your column definitions match the actual structure of your CSV! Otherwise, you'll get weird results (or worse, errors). Think of it as trying to fit a square peg into a round hole. It doesn’t end well.
Once your table is created, you can run SQL queries against it like you would any other database table. Want to know the average purchase amount of customers in California? SELECT AVG(purchase_amount) FROM your_table_name WHERE state = 'CA'; Boom! Data magic!

Putting It All Together (And Avoiding Catastrophic Errors)
So, there you have it. You've successfully uploaded your monstrous CSV to S3 and can now query it with Hive. You're basically a data wizard! High five!
A few parting words of wisdom:
- Test, test, test! Start with a small sample of your data before you unleash Hive on the entire giganto-file.
- Check your data types! Mismatched datatypes are the bane of every data analyst's existence.
- Use partitions! If your data is organized by date, region, or some other category, partitioning can drastically improve query performance. Think of it as organizing your filing cabinet.
- Don't be afraid to ask for help! The data community is vast and welcoming. There are plenty of forums and online resources where you can find answers to your questions.
Now go forth and analyze! And remember, always double-check your SQL before you hit that "run" button. You don't want to accidentally order 10 million toasters from Amazon. Unless… that's your actual business plan. In that case, carry on!