Support Vector Machine In Machine Learning Eli5 Reddit

Okay, picture this: you're at a party. And this isn't just any party. It's a pizza party! Half the pizzas are pepperoni, the other half are veggie. Your job? To magically, perfectly, draw a line that separates the pepperoni lovers from the veggie aficionados. You want it to be so good that anyone who walks in, you can look at their pizza preference and instantly know which group they belong to.
That, in a nutshell, is what a Support Vector Machine (SVM) does. Only instead of pizzas, it's dealing with data. And instead of partygoers, it's classifying... well, anything! Cats vs. dogs, spam vs. not spam, fraudulent transactions vs. legitimate ones. You name it, an SVM can probably try to separate it.
So, what's the magic behind the line? (Or hyperplane, if we wanna get fancy)
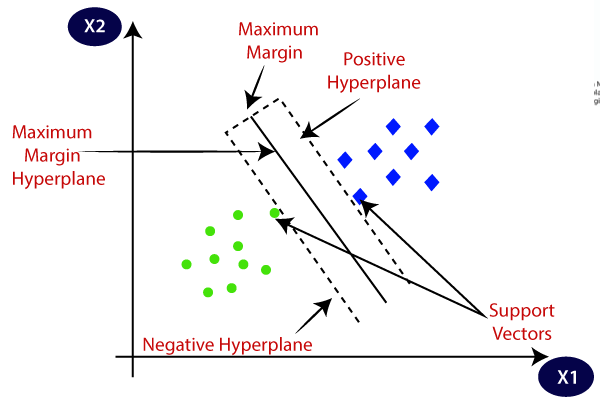
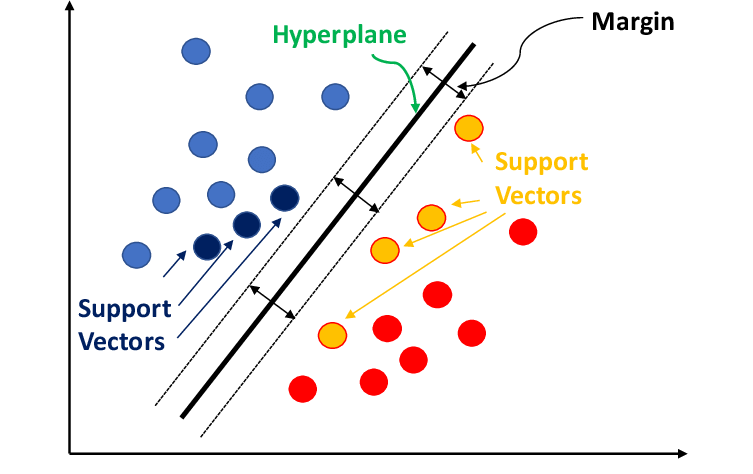
Here's where it gets interesting. An SVM doesn't just draw any line. It draws the best line. The line that gives it the most "breathing room" on either side. Think of it like building a fence between two groups of animals. You want the fence to be as far away from both groups as possible, right? So no one accidentally wanders over to the wrong side.
Must Read
Those "closest animals" to the fence? Those are your support vectors. They're the key players. The entire SVM is built around them. If you moved all the other points, the separating line might not change. But move those support vectors? Game over. Everything shifts.
(Side note: I always imagine support vectors as the grumpy gatekeepers of each data group. They're like, "You shall NOT pass... unless you have the correct data characteristics!")

Okay, Reddit's "Explain Like I'm Five" Version
Imagine you have two piles of Legos: red and blue. You want to draw a line on the table so all the red Legos are on one side, and all the blue Legos are on the other. An SVM finds the widest possible gap between the two piles, and draws the line right in the middle of that gap. The Legos closest to the line are the important ones because they define where that gap is.
See? Not so scary after all!
But what if the Legos are all mixed up? (The Non-Linear Case)
Ah, the classic "life isn't always perfect" scenario. What if your pepperoni and veggie pizzas are all jumbled together? What if you can't just draw a straight line to separate them?
This is where kernels come in. Kernels are like little magical transformers. They take your data and warp it into a higher dimension where you can draw a straight line. It's like lifting those mixed-up Legos onto a table that's curved in just the right way to separate the colors.

Common kernels include:
- Linear: A straight line (or hyperplane). Good for simple data.
- Polynomial: A curved line. Can handle more complex relationships.
- Radial Basis Function (RBF): A very powerful kernel that can create highly complex boundaries. But be careful! It can also overfit your data if you're not careful. (Overfitting means the model is too good at memorizing the training data and performs poorly on new data. Think of it like memorizing the answers to a test instead of actually understanding the material).
Choosing the right kernel is a bit of an art. You have to experiment and see what works best for your data. (It's like trying different sauces on your pizza. Some are amazing, some... not so much.)
Why use SVMs?
SVMs have a few advantages:
- Effective in high dimensional spaces: They can handle lots of features.
- Memory efficient: Because they only use the support vectors.
- Versatile: Different Kernel functions can be specified for the decision function.
But there are also some downsides:
- Prone to overfitting: Especially with complex kernels.
- Computationally expensive: Training can take a long time, especially on large datasets.
- Black box: It's not always easy to understand why an SVM makes a particular prediction.
So, there you have it. Support Vector Machines explained (hopefully) in a way that even your pizza-loving friend can understand. Go forth and classify!