Mongodb Journal And Oplog

Okay, picture this: you're baking a cake. Not just any cake, mind you, but the kind that wins blue ribbons at the county fair. You're meticulously following the recipe, adding a pinch of this, a dash of that... but then the phone rings. It's your Aunt Mildred with a juicy gossip session. You NEED to answer it!
So, you step away, leaving your perfectly prepped ingredients and half-mixed batter. That little mental snapshot of exactly where you left off? That, my friends, is kinda like MongoDB's journaling.
MongoDB's Journal: Your "Oops, I Did It Again" Safety Net
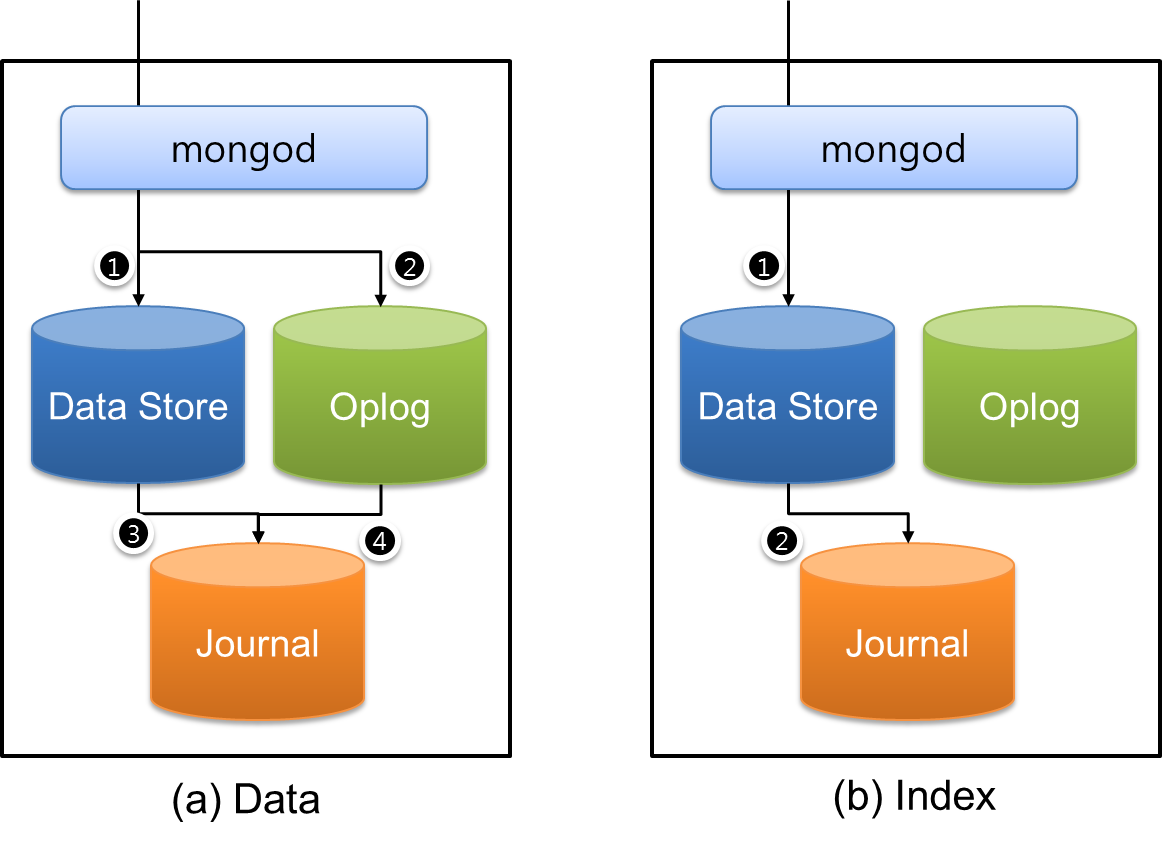
MongoDB, being the cool database it is, doesn't just blithely change data on disk. That'd be like randomly throwing ingredients into the mixing bowl and hoping for the best. Disaster! Instead, it keeps a meticulous record of every change, like writing down each step of your cake recipe as you go. This record is called the journal.
Must Read
Think of the journal as your "undo" button. If something catastrophic happens – power outage, rogue cat jumps on the keyboard, you name it – MongoDB can replay those journal entries and get back to the state it was in before disaster struck. It's like Aunt Mildred inadvertently saving your prize-winning cake!
Without journaling, you might end up with corrupted data. And nobody wants corrupted data. It’s the database equivalent of a burnt, sunken cake. Ugh.
The Oplog: The Gossip Network of MongoDB Clusters
Now, let's say you're not just baking one cake, but a whole BATCH of them simultaneously across multiple ovens (MongoDB servers in a cluster). Each oven needs to know what the others are doing, right? You don't want one oven accidentally adding too much sugar while another is completely missing the flour.
That's where the Oplog (Operations Log) comes in. It's like a giant community message board, or, let’s be honest, a really efficient gossip network. Every change made to the data on one server is written to its Oplog. Then, other servers in the cluster read that Oplog and apply the same changes to their own copies of the data.
Imagine this: one server updates a customer's address. That update goes into its Oplog. Other servers see this update in the Oplog and diligently update their own copies of that customer's address. Poof! All databases are in sync.
The Oplog is crucial for replication. Replication is what makes MongoDB so reliable and scalable. It allows you to have multiple copies of your data, so if one server goes down (oven breaks!), the others can keep serving data without missing a beat. It’s like having a backup baker (or three) ready to jump in.
It ensures data consistency across the entire cluster.

Journaling vs. Oplog: They're BFFs, Not Rivals
So, what’s the difference between the journal and the Oplog?
The journal is for data safety on a single server. It's your local "undo" button.
The Oplog is for data synchronization across multiple servers. It's the gossip network that keeps everything in sync.

They work together like peanut butter and jelly, or frosting and cake. You can't have a robust, reliable MongoDB setup without both of them doing their jobs. One ensures your individual server stays sane, the other ensures all your servers are singing from the same data hymn sheet.
Think of it this way: the journal is like your personal notes on the cake recipe, while the oplog is the shared google doc recipe for all the bakers baking together.
Next time you're using MongoDB and hear about the journal and Oplog, just remember that slightly stressful cake baking scenario. Hopefully, your data is in better shape than your cake would have been after that Aunt Mildred phone call!